La demanda de més capacitat d’emmagatzemar dades va creixent de forma exponencial de fa temps, però la tecnologia actual no pot oferir aquesta necessitat: els discs, cintes i demés mètodes tenen limitacions tant de mida, com de consum energètic o de la vida útil de les dades.
Així, per exemple, Facebook va obrir al 2013 un datacenter (lloc on s’instal·len tots de servidors per guardar-hi dades) per guardar-hi fotos i dades antigues que es consulten poc sovint (cold storage) amb capacitat per 1 EB (1.000.000.000 Gigabytes!) que ocupa uns 5600 metres quadrats i gasta aproximadament uns 10MW d’energia. Altres empreses (Google, Amazon, Microsoft, etc.) tenen instal·lacions similars arreu del món i no paren de obrir-ne de noves per mantenir el ritme d’emmagatzematge de dades que es necessita.
De fa molt de temps es va plantejant la possibilitat de fer servir l’ADN per guardar-hi informació i poder-la recuperar posteriorment. l’ADN té característiques a priori molt bones per guarda informació (de fet és el que fa en un ser viu), com són la alta durabilitat, ja que l’ADN pot sobreviure durant molts anys sense alteracions (s’ha recuperat ADN d’animals morts fa milers d’anys), és molt compacte, ja que son molècules que s’organitzen d’una forma molt petita i aprofitant força l’espai i es poden fer còpies de forma senzilla (com fa la natura en la reproducció cel·lular).
Les tecnologies actuals tenen una densitat d’informació en el millor dels casos d’uns 10 GB/mm³ i sembla que en un futur proper s’arribarà als 100 GB/mm³. Informació guarda en ADN podria arribar a una densitat de 1 EB/mm³.
Com sabem de l’escola, l’ADN es composa de 4 bases o elements bàsics, anomenats Adenina (A), Timina (T), Citosina (C) i Guanina (G).

components bàsics de l’ADN
Aquestes bases es poden posar en l’ordre que ens interessi per guardar-hi les nostres dades, fent que cada una de les bases correspongui a un codi binari determinat. Per exemple, es podria fer la següent correspondència:
- A = 00
- T = 01
- C = 10
- G = 11
D’aquesta manera codificar en bases d’ADN el text “HOLA” seria:
HOLA -> 01001000 01001111 01001100 01000001 -> TACA TAGG TAGA TAAT
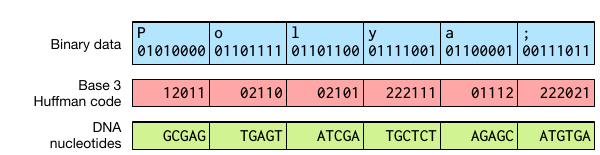
Una altre codificació fent servir ADN. (c) James Bornholt et al.
Amb les tècniques d’enginyeria genètica és possible aconseguir aquest ADN. De fet, avui dia es pot demanar a empreses especialitzades que ens fabriquin un tros de ADN amb la seqüència que se’ls demani. Després, quan calgui llegir la informació emmagatzemada, es poden fer servir tècniques ja disponibles per fer-ho en qualsevol laboratori de bioquímica.
Els principals problemes d’aquesta tècnica avui dia és el preu que té, ja que manipular ADN requereix de maquinaria cara i especialitzada personal entrenat. Tot i això, els avanços en aquest camp han automatitzat força els processos i reaccions i la maquinaria és cada cop més barata i assequible. Així, no es utòpic pensar que en uns anys aquestes màquines seran realment barates i disponibles pel gran públic (o per petites o mitjanes empreses).
L’altre problema d’aquest mètode és el temps d’accés a les dades guardades, donat que els mètodes bioquímics per manipular ADN requereixen normalment de moltes hores de diverses reaccions. Això, com l’anterior, també va millorant amb les successives millores en els processos i la maquinaria a usar.
En fi, i per acabar, si s’acaba usant aquesta tècnica de forma massiva per guardar-hi les nostres fotos, vídeos i textos, estarem reutilizant el que la natura fa milions d’anys que va usant per emmagatzemar i replicar la seva informació més valuosa: la vida.
Per saber-ne més
- Tech Companies Mull Storing Data in DNA, IEEE Spectrum
- Wikipedia, DNA digital data storage
- James Bornholt, Randolph Lopez, Douglas M. Carmean, Luis Ceze, Georg Seelig, and Karin Strauss. 2016. A DNA-Based Archival Storage System. SIGOPS Oper. Syst. Rev. 50, 2 (March 2016), 637-649. DOI: http://dx.doi.org/10.1145/2954680.2872397
-
R. Miller. Facebook builds exabyte data centers for coldstorage. link, 2013
Deja un comentario